Check out Continuous Integration Anti-Patterns.
Thursday, December 6, 2007
Tuesday, December 4, 2007
Continuous Integration Strategies (Part III)
How do you get your code to talk to you? Continuous integration is all about automated feedback. Beyond test reports and self-describing-code there are many techniques and tools that you can use to find out if you are producing "quality" code.
When you pick the right reports and integration them into the software build, the level of effort required to use these tools becomes very low (and we all know that developers are legendarily lazy).
Ideally, you should not have to remember to ask, the code should tell.
It's like being the parent of a teenager. At the dinner table you ask,
You would rather he came home with the enthusiasm of a kindergartener eager to tell you about his day as soon as he gets home. No effort on your part to ask, he just gushes unprompted,
So, recalling the computer adage, Garbage In, Garbage Out, we have carefully picked a select few reports that we feel give us a good measure of quality and integrated them into our build so that the feedback from CI is meaningful. Although several CI engines (we currently use Hudson) do have plugins to generate quality reports such as unit test results and test coverage, we feel it is important that developers have full access to run all the same reports that CI will run. Since we run maven, it is easy to plugin the reports of interest into the
So which reports do we run? Here's the rundown:
In addition, make full use of Maven's pom to declare all the sections that feed the default generated site, including:
Also, don't forget for maven multiproject builds to review the Dependency Convergence report. It will show all dependencies for all projects along with the versions of those dependencies. This will help you find dependencies your using inadvertently using multiple versions of.
Once you have these reports baked in, make the results easy to find. Use your CI engine to generate the maven site on a nightly basis and publish the results to a web server where developers or project stakeholders can find them.
After you spend the time and effort to identify which reports you want and get them configured and working correctly, make it repeatable for new projects by creating an archetype template project. This sets up a model pom.xml and project directory structure right off the bat for new projects. When it's there from the start, with no effort on the team's part, good things happen.
With a little up front effort, your code (with a little help from continuous integration) can talk to you. What are your strategies? How do you use CI to reveal code quality? I would be interested in hearing your strategies.
When you pick the right reports and integration them into the software build, the level of effort required to use these tools becomes very low (and we all know that developers are legendarily lazy).
Ideally, you should not have to remember to ask, the code should tell.
It's like being the parent of a teenager. At the dinner table you ask,
"So, how was school today?"
"I dunno."
"What did you learn?"
"Nothin'"
"Did anything interesting happen?"
"I dunno."
"How did you do on your history test"
(shrug)
You would rather he came home with the enthusiasm of a kindergartener eager to tell you about his day as soon as he gets home. No effort on your part to ask, he just gushes unprompted,
That's what continuous integration can do for you.
"Dad!! Guess what happened today at school?? It was so cool, I got an A+ on my spelling test!!"
So, recalling the computer adage, Garbage In, Garbage Out, we have carefully picked a select few reports that we feel give us a good measure of quality and integrated them into our build so that the feedback from CI is meaningful. Although several CI engines (we currently use Hudson) do have plugins to generate quality reports such as unit test results and test coverage, we feel it is important that developers have full access to run all the same reports that CI will run. Since we run maven, it is easy to plugin the reports of interest into the
<reporting> section of the pom. That keeps the report configurations in source control along with the code.So which reports do we run? Here's the rundown:
- Checkstyle. Validates source code against coding standards and reports any violations. We customized the ruleset, packaged it in a versioned jar and deployed it to our maven repository. Additionally, we forced it to run as part of every build in the
validatephase, and configured it to fail the build if violations are found. It's possible for an individual project to override the custom ruleset, but we don't encourage that. - PMD. Performs design time analysis of the source code against a standard ruleset. We customized the ruleset, packaged it in a versioned jar and deployed it to our maven repository. Additionally, we forced it to run as part of every build in the
validatephase, and configured it to fail the build if violations are found. - Test Results (surefire). This is a no-brainer. You want to see the results of your tests.
- Code Coverage (cobertura). Shows branch and line coverage for your source files. I think the key to using this metric is to not to set a percentage that the project team must meet, but to be smart about interpreting the trends. "Metrics are meant to help you think, not to do the thinking for you."
- Javadoc. Creates the API documentation for your project.
- Dashboard. Aggregates maven multiproject build reports into a single report page. This is critical so that developers and stakeholders don't have to hunt and drill down page after page to find the meaningful metrics you worked so hard to set up.
In addition, make full use of Maven's pom to declare all the sections that feed the default generated site, including:
- <scm> Source control management. New team members, for example will need to know the subversion URL for checkout.
- <developers> Identifies subject matter experts and feeds developer activity reports.
- <ciManagement> Identifies the CI engine being used and the URL to see the live status and force new builds.
- <issueManagement> Identifies the issue tracking system. I think there are maven plugins that will map issues to source control commits, providing bi-traceability of code to requirements.
Also, don't forget for maven multiproject builds to review the Dependency Convergence report. It will show all dependencies for all projects along with the versions of those dependencies. This will help you find dependencies your using inadvertently using multiple versions of.
Once you have these reports baked in, make the results easy to find. Use your CI engine to generate the maven site on a nightly basis and publish the results to a web server where developers or project stakeholders can find them.
After you spend the time and effort to identify which reports you want and get them configured and working correctly, make it repeatable for new projects by creating an archetype template project. This sets up a model pom.xml and project directory structure right off the bat for new projects. When it's there from the start, with no effort on the team's part, good things happen.
With a little up front effort, your code (with a little help from continuous integration) can talk to you. What are your strategies? How do you use CI to reveal code quality? I would be interested in hearing your strategies.
Friday, November 2, 2007
"The people are the network"
I found this fantastic read that expands globally off of my previous "organization-charts-get-in-the-way" post. It is long, but well worth the read.
Mob Rules (The Law of Fives)
This is my favorite quote from the text:
The summary is equally short and powerful:
Mob Rules (The Law of Fives)
This is my favorite quote from the text:
“The net regards hierarchy as a failure, and routes around it.”
The summary is equally short and powerful:
"Still, there is one thing I can recommend: have courage and keep moving. Standing still is not an option."
Wednesday, October 31, 2007
Continuous Integration Strategies (Part II)
Your CI environment is reporting a broken build. Now what?
I would like to stress that the faster you jump on the problem, the easier it is to solve. The changeset will be smaller and the person who most likely committed the offending code will have the changes he made freshly in mind.
There were some additional words of wisdom that recently circulated here that I would like to share with you. Props to Chad for nailing the importance of the entire team owning CI and having active communication about its status. The emphasis is mine.

I would like to stress that the faster you jump on the problem, the easier it is to solve. The changeset will be smaller and the person who most likely committed the offending code will have the changes he made freshly in mind.
It is a good policy that your team does not commit any additional changes to source control until the build is fixed.At times, it is too easy to ignore a broken build message, whether it is an email notification or a flashing red light or a lava lamp. Sometimes, the team will assume someone else is working the issue. I will always recommend having immediate and active communication that the problem is being worked so that positive control in maintained.
There were some additional words of wisdom that recently circulated here that I would like to share with you. Props to Chad for nailing the importance of the entire team owning CI and having active communication about its status. The emphasis is mine.
Make sure you're at least running unit tests before you commit. You can also have a buddy immediately update and build if you want feedback before waiting for Cruise Control to build. Also, after you commit, watch your email for a notification that the build has broken. If you're not going to be around, use a check-in buddy as mentioned previously.And that's the word.
If you've just committed a change and receive a build failure notification email, look into what's causing the problem asap. If it's a quick fix, just make the change and re-commit. Optionally reply to the build failure notification so that the team is aware you're putting in the fix. If it's not a quick fix, reply to the build failure notification stating that you're working the issue; again so the team is aware.
...The build is everyone's responsibility.
If you see that the build is remaining broken for a period of time, take it upon yourself to investigate. Find out if anyone is working the issue. If not, try to identify the problem and notify the party responsible so that the build can be fixed quickly. Now if you can't figure out what's wrong and identify who is responsible, take it upon yourself to fix the issue. If you are too busy, find someone that can. If you can't figure it out, ask for help. Use it as an opportunity to learn something. When you do finally find the problem, let the responsible party know what happened. Then they can learn something as well.
To sum it up, there shouldn't be any duration of time where the build is broken but isn't being looked into. While everyone should be watching after they commit to see if they've broken the build, it won't always get caught. You shouldn't be saying to yourself "I didn't break it so it's not my job to fix it".

Friday, October 19, 2007
Continuous Integration Strategies (Part I.I)
At the end of each successful continuous integration build and test suite, we label the workspace with a certified build tag within source control. This allows for bi-traceability from build sequence number to the tag name for QA purposes. Additionally, we can also do a simple lookup on the build number in Hudson to get a subversion revision number.
Below are two examples of how we have accomplished this.
Maven 1 and cruisecontrol and cvs:
We wrote a custom jelly goal that called ant's cvs task.
Notice the
Maven 2 and hudson and subversion:
In the maven pom.xml (or the parent pom.xml), specify the all the source control details so things become easier later. For example, our build includes:
Hudson provides maven a
[update:
Below are two examples of how we have accomplished this.
Maven 1 and cruisecontrol and cvs:
We wrote a custom jelly goal that called ant's cvs task.
<goal name="nct:createcertifiedtag">
<ant:cvs command="tag certified-build-${label}" />
</goal>
Notice the
"label" property. Cruisecontrol provides maven that property to use at runtime with the value set to the build number.
<maven projectfile="${PROJECT_ROOT}/project.xml" goal=clean install nct:certifiedtag" />
Maven 2 and hudson and subversion:
In the maven pom.xml (or the parent pom.xml), specify the all the source control details so things become easier later. For example, our build includes:
<scm>
<connection>scm:svn:https://svnhost/svn/sto/trunk</connection>
<developerConnection>scm:svn:https://svnhost/svn/sto/trunk</developerConnection>
<url>https://svnhost/svn/sto/trunk</url>
</scm>
Hudson provides maven a
"hudson.build.number" property to use at runtime populated with the build number. We use it by referencing that on the Goals line in the Hudson job configuration. Additionally, we made an improve over using an external process call to 'svn' by using the maven 2 SCM plugin.clean install scm:tag -Dtag=certified-build-${hudson.build.number} [update:
${hudson.build.number} seems to be buggy. I have successfully used ${BUILD_NUMBER} in its place]
Thursday, October 18, 2007
Continuous Integration Strategies (Part I)
Continuous integration is a powerful concept, usually associated with only compilation and unit testing. However, there is additional benefit to be had if you look beyond unit testing. I would like to present some strategies that I have tried that allow full suites of tests to be ran in orderly stages, from unit tests, to integration tests to acceptance tests. For this series unit tests are defined as single class tests with no external dependencies on network or container resources. Integration tests are white box testing of class interactions and acceptance tests are black box system tests.
This first post on the subject deals with strategies using maven and cruisecontrol. Later posts will move on to maven 2 and hudson.
First off, a lesson learned. When we first migrated from ant to maven, we were not sure how best to configure cruisecontrol to handle CI. Our code base is a large selection of components that comprise a toolset of capabilities. There are many small projects that build on each other, so there are many dependencies on our on artifacts. In fact, from a maven point of view, we could build our toolset with a single, rather large, multiproject build.
It seemed logical to map each component maven project (itself a multiproject consisting of api + implementations + tests) to a cruisecontrol project. That presented a nice one-to-one view of the system on the build status page. Each project was independently triggered via cvs commits. This seemed to work for awhile, but it became clear that this is highly unstable because commits spanning multiple cruisecontrol projects would trigger the builds in an unpredictable order, causing the build to break or tests to fail.
The lesson learned and correction we took was to not fight maven, but let it determine the build order from start to finish. So we created a single cruisecontrol project, pointed it at the top-most maven project.xml with the goal

The different types of tests were in different directories, as maven subprojects, under the component, so we were able to use
To facilitate the the including and excluding for the unit test pass, the
Hopefully, this first post in a series will help you think about ways to get more out of your CI environment. I'm curious to know what you think about the strategy we took and I invite you to share how you accomplish CI for your projects.
This first post on the subject deals with strategies using maven and cruisecontrol. Later posts will move on to maven 2 and hudson.
First off, a lesson learned. When we first migrated from ant to maven, we were not sure how best to configure cruisecontrol to handle CI. Our code base is a large selection of components that comprise a toolset of capabilities. There are many small projects that build on each other, so there are many dependencies on our on artifacts. In fact, from a maven point of view, we could build our toolset with a single, rather large, multiproject build.
It seemed logical to map each component maven project (itself a multiproject consisting of api + implementations + tests) to a cruisecontrol project. That presented a nice one-to-one view of the system on the build status page. Each project was independently triggered via cvs commits. This seemed to work for awhile, but it became clear that this is highly unstable because commits spanning multiple cruisecontrol projects would trigger the builds in an unpredictable order, causing the build to break or tests to fail.
The lesson learned and correction we took was to not fight maven, but let it determine the build order from start to finish. So we created a single cruisecontrol project, pointed it at the top-most maven project.xml with the goal
multiproject:install and the property -Dmaven.test.failure.ignore=true. Then for each component project we wanted test status granularity on, we created a cruisecontrol project that ran a custom maven plugin that scanned the test-results directory and failed that project if test failures were found. Additionally, that cruisecontrol project also used <merge> to aggregate maven's test-results files so our developers could drill down and see which test failed and the details why.
As a quick aside, Hudson has very nice maven integration that mimics (and improves on) this kind of setup automatically.Our next step was to enable a controlled progression of testing, where all unit test would run first, followed by integration tests only if all unit tests passed. This was accomplished in three steps: 1) one maven multiproject build responsible for compiling and unit testing, 2) a custom test failure check plugin (basically find + grep) serving as the go-no-go gate, then 3) another maven multiproject build running only integration tests. This three step orchestration was handled by a custom maven plugin running a mix of jelly and shell scripting.
The different types of tests were in different directories, as maven subprojects, under the component, so we were able to use
maven.multiproject.includes and maven.multiproject.excludes on the directory names to achieve steps 1) and 3) above.To facilitate the the including and excluding for the unit test pass, the
~/build.properties included these properties:maven.multiproject.includes=**/project.xmlFor the integration test pass, the
maven.multiproject.excludes=project.xml,*/project.xml,**/inttest/project.xml,**/tck/project.xml
~/build.properties included these properties:gcp.integration.multiproject.includes=**/inttest/project.xmland the plugin goal to actually run the integration tests looked like this:
gcp.integration.multiproject.excludes=**/tck/project.xml
<goal name="gcp:integration-tests">The crazy jelly maneuvering to get the includes and excludes properties to stick after the call to
<j:set var="usethese" scope="parent" value="${gcp.integration.multiproject.includes}"/>
<j:set var="notthese" scope="parent" value="${gcp.integration.multiproject.excludes}"/>
<j:set var="thisgoal" scope="parent" value="test:test"/>
${systemScope.put('maven.multiproject.includes', usethese)}
${systemScope.put('maven.multiproject.excludes', notthese)}
${systemScope.put('goal', thisgoal)}
<maven:maven descriptor="${CC_HOME}/checkout/gcp/project.xml" goals="multiproject:goal"/>
</goal>
maven:maven is a story for another day. (If you want a sneek peek, however, start here.) The concept of dynamically using maven properties to properly setup the integration test run should still be clear.Hopefully, this first post in a series will help you think about ways to get more out of your CI environment. I'm curious to know what you think about the strategy we took and I invite you to share how you accomplish CI for your projects.
Wednesday, October 10, 2007
Hudson, At Your Continuous Integration Service

I love Hudson. I have previously been a CruiseControl fan, but no longer. Hudson just works and has some excellent integration features with Maven2 and Subversion.
Generally, Hudson does this kind of stuff you would expect from a CI engine:
- Easy installation: Just java -jar hudson.war, or deploy it in a servlet container. No additional install, no database.
- Easy configuration: Hudson can be configured entirely from its friendly web GUI with extensive on-the-fly error checks and inline help. There's no need to tweak XML manually anymore, although if you'd like to do so, you can do that, too.
- Change set support: Hudson can generate a list of changes made into the build from CVS/Subversion. This is also done in a fairly efficient fashion, to reduce the load of the repository.
- RSS/E-mail Integration: Monitor build results by RSS or e-mail to get real-time notifications on failures.
- JUnit/TestNG test reporting: JUnit test reports can be tabulated, summarized, and displayed with history information, such as when it started breaking, etc. History trend is plotted into a graph.
- Distributed builds: Hudson can distribute build/test loads to multiple computers. This lets you get the most out of those idle workstations sitting beneath developers' desks.
- Plugin Support: Hudson can be extended via 3rd party plugins. You can write plugins to make Hudson support tools/processes that your team uses.
Since each build has a persistent workspace, we can go back in time to see that workspace to trace what happened. This means Hudson can do after-the-fact tagging and has permanent links to all builds, including "latest build"/"latest successful build", so that they can be easily linked from elsewhere.
I really like the matrix style jobs that you can create. For a matrix build, you can specify the JDK version as one axis and a slave Hudson (distributed builds) as another axis. Add to that a third axis of arbitrary property/values pairs that your build understands and can act on (e.g. think, maven
-PmyProfile or -Dapp.runSystemTests=true or -Ddatabase.flavor=mysql). This is powerful stuff right out of the box to support multiple compilers, OSes, etc., without having to create a new job for each configuration.For maven 2 projects, Hudson will autodiscover the
<modules> in a multiproject build and list them as sub-jobs in Hudson, complete with their own status and viewable workspaces. Links to project artifacts are linked to from the build status pages.The plugins are also starting to become plentiful. There are plugins for JIRA and Trac integration, code violations charting, publishing builds to Google calendar!, and many more. The one with the most potential I think is the Jabber plugin. Not only can it send IM notifications to an individual or a group, but the newest (cvs head) version comes with a bot that you can interact with to schedule builds, get project statuses, and monitor the build queue.
As always, sometimes small things mean a lot. An example I appreciate in Hudson is seeing the build in progress scrolling by via the browser. For CruiseControl, you would have to login to the build box and "tail -f" to get the same real-time information.
I'm not a groovy fan yet, but I was blown away when I found a built in groovy console right there in the web UI! You can use for trouble-shooting and diagnostics of your builds or plugins.
All in all, I am really, really impressed with Hudson as a product, and with the support and development going on around it. There is a new version released literally every week. It makes me, for the first time, want to contribute to an OSS project. This is good stuff. Check it out.
Monday, October 8, 2007
"Continuous Partial Attention"

I have blogged about being a "knowledge worker" before, but just found another good slideshare resource about it thanks to a link by Jim S.
The funniest thing was on slide 25 where a knowledge worker is described as having "Continuous Partial Attention."
I love that description.I work with several people who exhibit this trait and it is one the key characteristics, I think, that makes them successful in the workplace. To be sure, they are also criticized because their team-level focus seems to be lacking, however, this is made up for in the bigger benefit to the company. This is just another way to transcend team boundaries and have organization-wide impact.
And the reason it's funny is because it's true.
Tuesday, September 25, 2007
How to Host a Web Server at Home With Dynamic DNS
There are a lot of moving parts to get right to do this, and not a lot of good advice about how to do it successfully. I hope that my steps will help you get it right the first time.
My need for an at home hosted web service came from trying to develop a simple FaceBook application. I needed my application hosted somewhere quick and didn't want to pay for hosting. I'm comfortable using Tomcat to host my java applications, so I decided to try to host my application at my computer at home for easier development and debugging.
The trick for hosting a site that is publicly accessible is to be able to use a non-moving target for DNS servers to resolve. Since most people don't get a static IP for home use without paying extra for it, they are stuck with a Dynamic IP address. This means that behind the scenes, you are "leasing" the IP address for a period of time, after which it is revoked and another address is assigned to you. For normal internet use, this is a seamless operation, but for web hosting we need a little help. I suggest using the free service offered by DynDNS to do hostname to Dynamic IP mapping. With their service you can create a hostname (for example, http://codebeneath.dyndns.org, a subdomain to dyndns.org) and configure that to resolve to your current IP address, which they detect for you. Or if you prefer, hit IP Chicken :)
Now, you need a way to detect when your IP address changes and automatically update your DynDNS entry. There are standalone clients that can do this, but I was lucky enough to have the capability built into my router, a LinkSys BEFSX41.
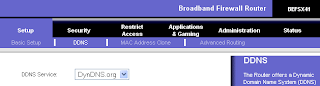
I have heard that some internet providers block port 80, so I decided just to use the default Tomcat port, which is 8080. If you stick with port 80 and run into problems, this may be the cause.
Next, we need to configure the router to forward all incoming port 8080 traffic to Tomcat. There are several ways to do this, depending on your router. The solution I don't recommend is enabling the DMZ Host setting (this is overkill and a potential security problem if you don't know what you are doing). The remaining alternatives are Port Range Forwarding and UPnP Forwarding. Port Range Forwarding is geared more for specialized internet applications such as videoconferencing or online gaming and can be used to forward an entire block of address at once.
For my case, I picked the simplest thing that worked: UPnP Forwarding. When I started, this was not the clear choice of how to do this, and many differing opinions steered me to conflicting directions. Compounding my confusion was an out-dated router firmware that provided administrative pages with different terminology and that did not even have UPnP Forwarding as an option.
Login to your router by pointing your browser at the admin URL. For my LinkSys, the admin URL is http://192.168.1.1/. The default username is blank (none) and the password is "admin"
Click "Applications and Gaming" > "UPnP Fowarding".
On the first blank line enter "tomcat" as the application name, "8080" as the Ext. Port, "TCP" as the protocol to allow, "8080" as Int. Port, your internal network address (e.g. 192.168.1.xxx) and mark the Enabled checkbox. To obtain your internal network address, open a command shell and type ipconfig. A gotcha to watch out for is that your internal address may also be dynamic if your router assigns addresses via DHCP. To avoid this, you could statically configure your network devices addresses, but for my purposes DHCP was OK.
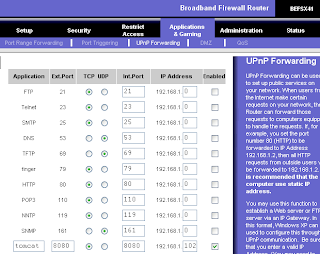
Save the router settings and close your browser.
Start Tomcat and make sure you can access http://localhost:8080. If so, then try the public address you created at DynDNS (in my case http://codebeneath.dyndns.org:8080). If all is well, you should be seeing the Tomcat welcome page! Deploy your web application and happy web hosting.

My need for an at home hosted web service came from trying to develop a simple FaceBook application. I needed my application hosted somewhere quick and didn't want to pay for hosting. I'm comfortable using Tomcat to host my java applications, so I decided to try to host my application at my computer at home for easier development and debugging.
The trick for hosting a site that is publicly accessible is to be able to use a non-moving target for DNS servers to resolve. Since most people don't get a static IP for home use without paying extra for it, they are stuck with a Dynamic IP address. This means that behind the scenes, you are "leasing" the IP address for a period of time, after which it is revoked and another address is assigned to you. For normal internet use, this is a seamless operation, but for web hosting we need a little help. I suggest using the free service offered by DynDNS to do hostname to Dynamic IP mapping. With their service you can create a hostname (for example, http://codebeneath.dyndns.org, a subdomain to dyndns.org) and configure that to resolve to your current IP address, which they detect for you. Or if you prefer, hit IP Chicken :)
Now, you need a way to detect when your IP address changes and automatically update your DynDNS entry. There are standalone clients that can do this, but I was lucky enough to have the capability built into my router, a LinkSys BEFSX41.

I have heard that some internet providers block port 80, so I decided just to use the default Tomcat port, which is 8080. If you stick with port 80 and run into problems, this may be the cause.
Next, we need to configure the router to forward all incoming port 8080 traffic to Tomcat. There are several ways to do this, depending on your router. The solution I don't recommend is enabling the DMZ Host setting (this is overkill and a potential security problem if you don't know what you are doing). The remaining alternatives are Port Range Forwarding and UPnP Forwarding. Port Range Forwarding is geared more for specialized internet applications such as videoconferencing or online gaming and can be used to forward an entire block of address at once.
For my case, I picked the simplest thing that worked: UPnP Forwarding. When I started, this was not the clear choice of how to do this, and many differing opinions steered me to conflicting directions. Compounding my confusion was an out-dated router firmware that provided administrative pages with different terminology and that did not even have UPnP Forwarding as an option.
I do recommend updating your router's firmware to avoid the same confusion I had and to have the latest security patches in place.
Login to your router by pointing your browser at the admin URL. For my LinkSys, the admin URL is http://192.168.1.1/. The default username is blank (none) and the password is "admin"
If you still have your default password, change it immediately before proceeding further!

Click "Applications and Gaming" > "UPnP Fowarding".
On the first blank line enter "tomcat" as the application name, "8080" as the Ext. Port, "TCP" as the protocol to allow, "8080" as Int. Port, your internal network address (e.g. 192.168.1.xxx) and mark the Enabled checkbox. To obtain your internal network address, open a command shell and type ipconfig. A gotcha to watch out for is that your internal address may also be dynamic if your router assigns addresses via DHCP. To avoid this, you could statically configure your network devices addresses, but for my purposes DHCP was OK.

Save the router settings and close your browser.
Start Tomcat and make sure you can access http://localhost:8080. If so, then try the public address you created at DynDNS (in my case http://codebeneath.dyndns.org:8080). If all is well, you should be seeing the Tomcat welcome page! Deploy your web application and happy web hosting.

Tuesday, September 18, 2007
Thursday, September 13, 2007
tHERE gOES gRAVITY
What's another word for 'empowered'? I don't like it because it is overused as a corporate buzzword and under appreciated as a game-changing concept. It's the concept that I like. In your company, do you feel free to cross those invisible corporate boundaries to make things happen? To discuss, collaborate, act? I'm lucky enough to work for a company that makes me feel that way. And it's not because they make a big announcement heralding the idea to the masses: "You are empowered to make decisions".
I've heard that before and it wasn't true. There were still job titles, egos and chains of command to contended with.
'Empowered' sounds like you're being granted permission from those higher up the food chain to act. I guess the people surrounding me today, the CEO, the CIO, and my co-workers make me want to be Accountable; a concept I believe is self-granted. If I have an idea, I can own it, grow it and make it work. And not as a solo effort, either. We are encouraged to reach out and work directly with the people who can make ideas into reality.
The actions I see on a daily basis speak louder than any words to confirm this. After being hired, I met several of people in senior leadership positions in the company. As an example of their commitment to keep the communication channels open, they were adamant that there should not be an company organization chart.


No artificial power structures in place or asking permission from the boss to talk to your peers who happen to work in a different department or on a different contract. As an organization, we are very flat, by design, and it Just Works. It's like a big tree, whose branches are weighed down by an ice storm, all suddenly shake free their icy repression and spring up to the same height as the highest branch.
This is individual accountability to own and promote ideas and to collaborate as a next generation enterprise using lightweight, online tools (including the phone!) to make it easy. This is collaborating on ideas on your corporate wiki. This is sharing your bookmarked feeds collectively through Yahoo Pipes. This is about sharing your experiences and knowledge by blogging about it. This is keeping a pulse on new technologies, not for your team, but for other teams in the company. This is a call.
As Charlie says, "Advertise yourself", your knowledge and what you are passionate about, so when the time comes, people will also reach out to you to collaborate with.
Even with obstacles removed from your path, it can still be tough to follow through. I am out of my personal comfort zone on a regular basis. However, I know it's the way forward, for my company, but most importantly for me. It's my way of providing leadership at work. I can't do it with words. I have to do it by leading by example.
You can, too. Make it an infectious attitude. Lose Yourself.
I've heard that before and it wasn't true. There were still job titles, egos and chains of command to contended with.
'Empowered' sounds like you're being granted permission from those higher up the food chain to act. I guess the people surrounding me today, the CEO, the CIO, and my co-workers make me want to be Accountable; a concept I believe is self-granted. If I have an idea, I can own it, grow it and make it work. And not as a solo effort, either. We are encouraged to reach out and work directly with the people who can make ideas into reality.
The actions I see on a daily basis speak louder than any words to confirm this. After being hired, I met several of people in senior leadership positions in the company. As an example of their commitment to keep the communication channels open, they were adamant that there should not be an company organization chart.
Not this:

This:

No artificial power structures in place or asking permission from the boss to talk to your peers who happen to work in a different department or on a different contract. As an organization, we are very flat, by design, and it Just Works. It's like a big tree, whose branches are weighed down by an ice storm, all suddenly shake free their icy repression and spring up to the same height as the highest branch.
oh, tHERE gOES gRAVITY!Being in an environment like this has changed me. I am no longer in a cubicle reporting to a single boss. I am one of many influences in the company who increasingly don't see team boundaries, we see Singularity. We see opportunities to improve our business and our culture and we're making it happen.
This is individual accountability to own and promote ideas and to collaborate as a next generation enterprise using lightweight, online tools (including the phone!) to make it easy. This is collaborating on ideas on your corporate wiki. This is sharing your bookmarked feeds collectively through Yahoo Pipes. This is about sharing your experiences and knowledge by blogging about it. This is keeping a pulse on new technologies, not for your team, but for other teams in the company. This is a call.
This is the Manifesto that I believe in.
As Charlie says, "Advertise yourself", your knowledge and what you are passionate about, so when the time comes, people will also reach out to you to collaborate with.
Even with obstacles removed from your path, it can still be tough to follow through. I am out of my personal comfort zone on a regular basis. However, I know it's the way forward, for my company, but most importantly for me. It's my way of providing leadership at work. I can't do it with words. I have to do it by leading by example.
You can, too. Make it an infectious attitude. Lose Yourself.
Thursday, August 30, 2007
Simple SOAP posting from the command line
From the linux command line, you can do use
where the
curl to submit a soap file to a URL.curl -H "Content-Type: text/xml; charset=utf-8" \
-H "SOAPAction:" \
-d @soap.txt \
-X POST http://localhost:18181/httpWSDLService/httpWSDLPort
where the
@ specifies a file as input and soap.txt is the file.
Tuesday, August 28, 2007
Microformats: A DoD Use Case
Microformats have been around awhile, but I have just recently took the time to find out what they are and what they can do. A good starting place I can recommend is microformats.org. Basically, using microformats means adding attributes to existing html elements to enhance the meaning of the content.
The physical address presented on this blog is marked up, for example, as a hCard.
This could be thought of as a lightweight semantic web enabler. And the beauty of course is the simplicity of it. It is suitable for use in marking up HTML, RSS, Atom or XML.
So now the question: what could be accomplished with microformats? What might be a scenario in a military domain?
The physical address presented on this blog is marked up, for example, as a hCard.
<div class="vcard">
<div class="adr">
<div class="org fn">
<div class="organization-name">Gestalt-LLC</div>
</div>
<div class="street-address">320 East 4th Street</div>
<span class="locality">Joplin</span>,
<abbr class="region" title="Missouri">MO</abbr>
<span class="postal-code">65801</span>
</div>
</div>
This could be thought of as a lightweight semantic web enabler. And the beauty of course is the simplicity of it. It is suitable for use in marking up HTML, RSS, Atom or XML.
So now the question: what could be accomplished with microformats? What might be a scenario in a military domain?
- A soldier is observing and recording enemy aircraft taking off from a hostile airfield. He microblogs about it on a ruggedized PDA marking up the aircraft information in a military airframe microformat (date, time, aircraft type, payload configuration, number of aircraft in formation, observed tail numbers, for example).
- This is an unanticipated observation, so the data may not be immediately useful or actionable.
- But, Google will find it (and yes, the DoD has Google appliances running on their classified networks). Not necessarily based on the microformating, but based on its normal searchable content. Technorati, however, does have a microformat search engine.
- These search results are microformat parsed and fed into a Temporal Analysis System (TAS) whose job in life is to predict the future by comparing recent events with similar historical events chains and their outcomes.
- It turns out that what the soldier observed, perhaps 10 cargo aircraft, all with extra fuel pods, bearing NNW, from grid reference 18SUU8401, is a 90% predictor that the hostile battalion will be mobilizing and deploying in 72 hours.
- Useful information to know derived from someone outside the normal chain of command and information flow!
Monday, August 27, 2007
Source Control Tips for Netbeans Projects
This post is specifically for SOA projects centered around JBI composite applications and service units, but I think 90% would still apply to any project type. If you create the projects inside of NetBeans and use an external source control tool, like SmartSVN, these are the directories you'll want to exclude and ignore.
For a service unit project, like a BPEL module, exclude
For a service unit project, like a BPEL module, exclude
buildnbproject/private
builddistnbproject/privatesrc/jbiasasrc/jbiServiceUnits
Properties > Edit Ignore Patterns.... Enter the directory names, save and don't forget to commit!
Tuesday, August 21, 2007
Using BPELs doXslTransform() function
As a improvement to my previous design of aggregating RSS feeds from various continuous integration systems, I wanted to do a simple XSL transform to make my post-processing easier. If I could get each element to be on it's own line, then things become much easier for the later parsing that I have to do.
Given that I am using OpenESB and JBI to accomplish my goals, I have two choices of how to perform the transform. 1) Use the XSLTSE or 2) Use the BPEL function doXslTransform(). I choose the latter option because it was the simplest thing that worked. (I will have another post about using the XSLTSE though. Stay tuned!)
To start, I created the XSL stylesheet that takes input and produces output that validated to the same schema (rssbcext.xsd in this case). Then in my Netbeans BPEL editor, I clicked on the Assign1 operation.

This brings up the BPEL Mapper. Add the doXslTranform functoid (and no, I did not come up with that term).

The Netbeans tooling is not yet complete for this function, so we have to add the stylesheet
Clean and Build, then deploy to Glassfish. That's all there is to it. My RSS feeds are now in a compact format, making my processing easier and saving valuable disk space. :)
Given that I am using OpenESB and JBI to accomplish my goals, I have two choices of how to perform the transform. 1) Use the XSLTSE or 2) Use the BPEL function doXslTransform(). I choose the latter option because it was the simplest thing that worked. (I will have another post about using the XSLTSE though. Stay tuned!)
To start, I created the XSL stylesheet that takes input and produces output that validated to the same schema (rssbcext.xsd in this case). Then in my Netbeans BPEL editor, I clicked on the Assign1 operation.

This brings up the BPEL Mapper. Add the doXslTranform functoid (and no, I did not come up with that term).

The Netbeans tooling is not yet complete for this function, so we have to add the stylesheet
file-name as a URN string literal. In my case it was 'urn:stylesheet:citransform.xsl'. Drag the RSSConsumerWSDLOperationIn.part1 to the node-set and drag the return-node to the FileWSDLOperationIn.part1.Clean and Build, then deploy to Glassfish. That's all there is to it. My RSS feeds are now in a compact format, making my processing easier and saving valuable disk space. :)
Friday, August 17, 2007
Using JBI To Keep An Eye on Continuous Integration
I'm a big fan of Continuous Integration. We thrive on it at work to get feedback for our code integration on a constant basis. As part of a bigger company effort, we wanted to be able to create team dashboards showing CI health (server up, building, not broken too long, etc). The teams here mostly use CruiseControl, but we also a few teams utilizing Hudson and Luntbuild.
So what's an easy way to keep tabs on 3 different build systems? RSS of course!
CruiseControl publishes out an RSS feed, Luntbuild publishes an ATOM feed and Luntbuild recently added RSS and ATOM feeds (committed, but not distributed yet, as of 1 Aug 2007).
Enter JBI, Open-ESB, and the RSS Binding Component (BC).
Start by downloading the latest Open-ESB/Glassfish bundle. Start up Netbeans. To subscribe to multiple RSS feeds via the RSS BC, we need an RSS provider and an RSS consumer composite application.
Create the provider BPEL module by creating a new Netbeans project (New Project > Service Oriented Architecture > BPEL Module). Name it CIProviderBpelModule. Now we need to import two xml schemas into our project (rssbcext.xsd and wsaext.xsd). Follow the steps outlined here to do the imports.
Create two WSDLs, one for http and the other for rss, with the New WSDL Document wizard.
On the Name and Location step, name the rss WSDL "rssciprovider" and import the rssbcext.xsd schema, By File, with a prefix of "rssbcext". On the Concrete Configuration section, make sure RSS is selected as the Binding Type.
On the Name and Location step, name the http WSDL "httpci" and import the wsaext.xsd schema, By File, with a prefix of "wsaext". On the Concrete Configuration section, make sure SOAP is selected as the Binding Type.
At this point both WSDLs should validate (Alt+Shift+F9) correctly. This will make sure all schemas are imported correctly.
Open the httpci.wsdl and navigate to the request message part1. Click the element and then in the Properties pane of Netbeans, change the element attribute from
Open the rssciprovider.wsdl and navigate to the request message part1. Change the type to an wsaext element EndpointReferenceList as above. You can also remove the reply message and the output from the operation and binding as this will be an In-Only message. For the binding operation, change the input to
Validate the WSDLs and then Process Files > New > BPEL Process. Give it a name "rssProviderBpelProcess". Drag and drop the two WSDLs into the process flow diagram; this will create partner links. Name them "httpPartnerLink" and "rssProviderPartnerLink". Swap Roles for the rssPartnerLink to "Partner Role".
From the Palette pane, drag and drop Receive, Assign, Invoke, Assign and Reply operations onto the BPEL flow. Edit Receive1 to point to the httpPartnerLink and create an input variable. Edit Invoke1 to point to rssProviderPartnerLink and create an input variable. Edit Reply1 to point to httpPartnerLink and create an output variable. Click Assign1 and using the BPEL Mapper pane at the bottom of Netbeans drag a line from HttpciOperationIn.part1 to RSSciOperationIn.part1 (ignore data types don't match warning).
For the SOAP response, we will just hardcode something to acknowledge the RSS provider is subscribed. Click Assign2 and using the BPEL Mapper create a String Literal with a value of "Done.". Drag a line from the String Literal to HttpciOperationOut.part1.
Validate the BPEL file.
Create a new Composite Application project "CIProviderCA" and add the JBI Module project CIProviderBpelModule to it. Clean and build.
Create the consumer BPEL module by creating a new Netbeans project named CIConsumerBpelModule. Import the rssbcext.xsd schema into the project.
Create a rssciconsumer.wsdl with the rssbcext.xsd schema imported as before. Make sure "RSS" is selected as the Binding Type. Edit the wsdl and change the message part element to
Create a fileci.wsdl with the rssbcext.xsd schema imported as before. Make sure "File" is selected as the Binding Type. Edit the wsdl and change the message part element to
Validate the WSDLs and then create a new BPEL Process named "rssConsumerBpelProcess". Drag and drop the two WSDLs into the process flow diagram; this will create partner links. Name them "filePartnerLink" and "rssConsumerPartnerLink". Swap Roles for the filePartnerLink to "Partner Role".
From the Palette pane, drag and drop Receive, Assign, Invoke operations onto the BPEL flow. Edit Receive1 to point to the rssConsumerPartnerLink and create an input variable. Edit Invoke1 to point to filePartnerLink and create an input variable. Click Assign1 and using the BPEL Mapper drag a line from RssciconsumerOperationIn.part1 to FileciOperationIn.part1 (ignore data types don't match warning).
Validate the BPEL file.
Create a new Composite Application project "CIConsumerCA" and add the JBI Module project CIConsumerBpelModule to it. Clean and build.
Start glassfish and deploy both JBI Composite Applications to it.
In the provider CA project, create a test a new test case, pointing it to the httpci.wsdl and the httpciOperation. Sweeeeeeeeet. Edit the test case input. Each Endpoint reference only needs the Address element to be valid. Add as many as EndpointRerefences as you need to the EndpointRerefenceList. Run the test.
Look in
So what's an easy way to keep tabs on 3 different build systems? RSS of course!
CruiseControl publishes out an RSS feed, Luntbuild publishes an ATOM feed and Luntbuild recently added RSS and ATOM feeds (committed, but not distributed yet, as of 1 Aug 2007).
And I don't want to write any code to aggregate these feeds together.
Enter JBI, Open-ESB, and the RSS Binding Component (BC).
Start by downloading the latest Open-ESB/Glassfish bundle. Start up Netbeans. To subscribe to multiple RSS feeds via the RSS BC, we need an RSS provider and an RSS consumer composite application.
Create the provider BPEL module by creating a new Netbeans project (New Project > Service Oriented Architecture > BPEL Module). Name it CIProviderBpelModule. Now we need to import two xml schemas into our project (rssbcext.xsd and wsaext.xsd). Follow the steps outlined here to do the imports.
The WS-Addressing extension schema is used to have access to the element EndpointReferenceList, which we'll use to feed the RSS feed URLs into the system via a SOAP request.
Create two WSDLs, one for http and the other for rss, with the New WSDL Document wizard.
On the Name and Location step, name the rss WSDL "rssciprovider" and import the rssbcext.xsd schema, By File, with a prefix of "rssbcext". On the Concrete Configuration section, make sure RSS is selected as the Binding Type.
On the Name and Location step, name the http WSDL "httpci" and import the wsaext.xsd schema, By File, with a prefix of "wsaext". On the Concrete Configuration section, make sure SOAP is selected as the Binding Type.
At this point both WSDLs should validate (Alt+Shift+F9) correctly. This will make sure all schemas are imported correctly.
Open the httpci.wsdl and navigate to the request message part1. Click the element and then in the Properties pane of Netbeans, change the element attribute from
type="xsd:string" to element="wsa:EndpointReferenceList" Do the same for the reply message part1. (Make sure you pick element and not type. Thanks James!).Open the rssciprovider.wsdl and navigate to the request message part1. Change the type to an wsaext element EndpointReferenceList as above. You can also remove the reply message and the output from the operation and binding as this will be an In-Only message. For the binding operation, change the input to
Validate the WSDLs and then Process Files > New > BPEL Process. Give it a name "rssProviderBpelProcess". Drag and drop the two WSDLs into the process flow diagram; this will create partner links. Name them "httpPartnerLink" and "rssProviderPartnerLink". Swap Roles for the rssPartnerLink to "Partner Role".
From the Palette pane, drag and drop Receive, Assign, Invoke, Assign and Reply operations onto the BPEL flow. Edit Receive1 to point to the httpPartnerLink and create an input variable. Edit Invoke1 to point to rssProviderPartnerLink and create an input variable. Edit Reply1 to point to httpPartnerLink and create an output variable. Click Assign1 and using the BPEL Mapper pane at the bottom of Netbeans drag a line from HttpciOperationIn.part1 to RSSciOperationIn.part1 (ignore data types don't match warning).
For the SOAP response, we will just hardcode something to acknowledge the RSS provider is subscribed. Click Assign2 and using the BPEL Mapper create a String Literal with a value of "Done.". Drag a line from the String Literal to HttpciOperationOut.part1.
Validate the BPEL file.
Create a new Composite Application project "CIProviderCA" and add the JBI Module project CIProviderBpelModule to it. Clean and build.
Halfway there!
Create the consumer BPEL module by creating a new Netbeans project named CIConsumerBpelModule. Import the rssbcext.xsd schema into the project.
Create a rssciconsumer.wsdl with the rssbcext.xsd schema imported as before. Make sure "RSS" is selected as the Binding Type. Edit the wsdl and change the message part element to
element="rssbcext:EntryList". Change the operation input to Create a fileci.wsdl with the rssbcext.xsd schema imported as before. Make sure "File" is selected as the Binding Type. Edit the wsdl and change the message part element to
element="rssbcext:EntryList". Remove all output references; In-Only again. Change the operation input to Validate the WSDLs and then create a new BPEL Process named "rssConsumerBpelProcess". Drag and drop the two WSDLs into the process flow diagram; this will create partner links. Name them "filePartnerLink" and "rssConsumerPartnerLink". Swap Roles for the filePartnerLink to "Partner Role".
From the Palette pane, drag and drop Receive, Assign, Invoke operations onto the BPEL flow. Edit Receive1 to point to the rssConsumerPartnerLink and create an input variable. Edit Invoke1 to point to filePartnerLink and create an input variable. Click Assign1 and using the BPEL Mapper drag a line from RssciconsumerOperationIn.part1 to FileciOperationIn.part1 (ignore data types don't match warning).
Validate the BPEL file.
Create a new Composite Application project "CIConsumerCA" and add the JBI Module project CIConsumerBpelModule to it. Clean and build.
Start glassfish and deploy both JBI Composite Applications to it.
In the provider CA project, create a test a new test case, pointing it to the httpci.wsdl and the httpciOperation. Sweeeeeeeeet. Edit the test case input. Each Endpoint reference only needs the Address element to be valid. Add as many as EndpointRerefences as you need to the EndpointRerefenceList. Run the test.
Look in
C:\Temp (or whatever directory the file service port referenced) and you should see a ci-feeds.xml file with an aggregation of all the continuous integration RSS/ATOM feeds in it.
Monday, August 13, 2007
Accountability and the Knowledge Worker
Are you a Knowledge Worker? Fred Nickols really sets the framework for how companies can really make a difference when they are drive by a new breed of accountable individual (any he did this back in the '80s)

- I seek out and I set direction.
- I resist supervision; I welcome support.
- I work at my own pace within the constraints posed by the situation.
- I put my name on what I do -- and the names of those who contribute in any way to any endeavor for which I am accountable.
- I promote, praise, recognize and reward accomplishment and service.
- I contribute more than I consume.
- I seek control over myself and influence over events about me.
- I care about my work -- it is a reflection of me.
- I care about the enterprise of which I am a part and I will do my best to protect it against all threats -- whether they are external or internal.
- I care about the people with whom I work; they are not just co-workers or colleagues -- they are also friends, allies and comrades.
- I refuse to simply "obey orders" and "go along with the program."
- I will hold my superiors as accountable for their actions as they hold me accountable for mine.
- I will not turn a "blind eye" or a "deaf ear" to wrongdoing at any level of any organization of which I am a part.
- I will do my best to share what I know with those who are interested in learning from me and I will do my best to learn from those who are skilled, knowledgeable or competent in areas I am not.
- I will at all times strive to advance and improve the knowledge base that undergirds my skills, abilities and accomplishments.
Wednesday, August 1, 2007
Testing Karma
I think Earl said it best when he said "Do good things, and good things happen." What kind of good things? How about good software engineering practices? Use Case modeling, sequence diagramming, continuous integration and automated testing are all good starts.
Diagrams and models are good because they clearly communicate intent. The picture is worth more than a thousand words if a stakeholder (or peer) can talk to the diagram and say something as simple as "delete that line and add this one", or "change the arrow to point the other way on the sequence flow". Then everyone goes, "ah... now I get it". Practices like these definitely pay dividends over waiting to fix any architectural flaw later in the lifecycle of the system.
Creating automated tests, too, are equally valuable. And not hard. And can help you develop better code. Sometimes writing unit tests after the fact can be a real head-scratcher. Thinking about the code and the test as a singular unit can help structure the code in better ways. "When you think of code and test as one, testing is easy and code is beautiful."
Also from artima :
- The perfect is the enemy of the good. An imperfect test today is better than a perfect test someday.
- Rejoice when they pass; Rejoice when they fail.
Be creative and flexible when writing your tests. Write that ugly test for the "untestable" code. Take that first step and good things start to happen. And when you're walking, you won't notice the steps because they will have become habit.
Unit testing advice
Good stuff from the guys over at the Google Testing Blog.
I had never really given much thought to naming the methods in a unit test class. But if you give it a little though, the method names by themselves can read like a list of low-level functional requirements.
Why write test methods like
I had never really given much thought to naming the methods in a unit test class. But if you give it a little though, the method names by themselves can read like a list of low-level functional requirements.
Why write test methods like
-
testClient()or -
testURI()or -
testRun()
testTryToInvokeServiceBehindFirewallDirect()ortestCompiledInputCommandIsConvertedAndDispatched()ortestWriteDataToFile()?
The rest of the world is so smart
North America really needs to get with the world program. Witness:
Paper Sizes:
Date and Time:
and of course the Metric System:
Words from the guy who was responsible for the Google SOAP API
Nelson Minar doesn't work for Google anymore and bears no ill will that Google yanked the SOAP API that he was responsible for. If fact, he has a pretty negative view of SOAP, its interoperability problems and brittleness.
But I particularly liked the last sentence of his post, "Just do something that works". It ties in nicely with my last post, Solving The Problem in a Very Good (Not Perfect) Way.
Perfect is the enemy of Very Good
I found this a good, quick read and helpful as a reminder on how to tackle hard problems. My takeaway was to take action and not wait until "all the data is in" before making a decision. In short, deliver the Very Good as opposed to Perfection. As the CEO of the company I work for said recently, working in a vaguely correct direction is better than standing still. [Update: In the software business, the remark about "working in a vaguely correct direction is better than standing still" works because of Scrum. If you are talking to your client and demonstrating your solution every 30 days, your can have that meaningful conversation where both parties refine the problem and the solution together.]
The full discussion for the quotes below is here: http://pliantalliance.org/?p=34
Never let perfect stand in the way of very good.
It may be tempting to wait until you have the time, the knowledge, or the inclination to design the “perfect” solution, especially if you aim to solve the real problem. However, you must temper this instinct with practicality. While it may look like you are holding out for “the perfect solution” (that solves the whole, real problem), what you are really doing is preventing “the very good solution” that can be applied in the interim. We must recognize that perfection can only be approached asymptotically through evolution of design and implementation: in essence by refining our deployed very good solutions to make them more perfect. Solving the real problem should be applied where scope allows and it should guide our path to tell us where perfect is, but we are allowed to get there in more than one step. Very good solutions have value, and value delayed is value lost.
The same site had a good collection of quotes regarding change and flexibility:
"He that will not apply new remedies must expect new evils; for time is the greatest innovator.."
Subscribe to:
Posts (Atom)